
Spring 2007
The first 50 EEMBC Journal subscribers who successfully sign up a colleague for a free E-mail subscription to EEMBC Journal will receive a gift that money can’t buy: a copy of Steve Leibson’s Designing SOCs with Configured Cores: Unleashing the Tensilica Xtensa and Diamond Cores signed by the author. This essential reference for system-on-chip designers by Tensilica’s Leibson uses EEMBC benchmarks to compare Tensilica cores with competitive devices. Regular price at Amazon.com: $59.95. Your free copy with Steve’s autograph: Priceless. Click here to enter.
EEMBC Calendar
Shay Gal-On, Director of Software Engineering at EEMBC, will present “Performance and Energy Benchmarks for Multicore Platforms” at the Multicore Expo, March 29, at 1:15-1:45 p.m., at the Santa Clara Convention Center. He’ll be talking about EEMBC’s new multicore benchmarks and providing preliminary details of the methodology being developed within the consortium for dealing with multicore processors. Multicore Expo will also feature an EEMBC exhibit. For details on show hours, visit www.multicore-expo.com.
At the Embedded Systems Conference on April 5 at 8:30 a.m., Gal-On will present “Real-Time Benchmarks For Automotive Applications,” a class that gives an overview of the challenges of developing and implementing automotive benchmarks that can be generated to match specific OEM specifications and evolve in tandem with automotive standards as soon as requirements are known, rather than requiring a long development cycle. The conference is taking place at the McEnery Convention Center in downtown San Jose. EEMBC will also be present within the Power.org exhibit (booth 1216) on a Power Architecture pod being co-sponsored by AMCC, EEMBC, Freescale, Green Hills, and IBM.
“Key Factors to Improve Microcontroller Performance and Features” is the title of a presentation being given by Patrick Leteinturier of Infineon Technologies and chair of EEMBC's Automotive Subcommittee at SAE on April 19 at 9 a.m. in Room W2-64 of Cobo Center. His paper will address the factors needed to increase overall data throughput and provide the right microcontroller features needed to satisfy future drivetrain requirements, including the microcontroller architecture, cores, memories, silicon technologies, assembly/packaging, and development tools. The SAE World Congress is being held in Detroit April 16 – 19.
At this year’s Embedded Systems Expo (ESEC) being held May 16-18 at the Tokyo Big Sight, Markus Levy will be discussing standards and benchmarks for the embedded multicore industry being developed respectively by the Multicore Association and EEMBC. His presentation, entitled “Multicore Standards Support Embedded Software Development and Performance Analysis,” takes place May 16 from 2:50 to 4:10 p.m.
| Letter from the President History will recall that 1997 was the year the Packers beat the Patriots in the Super Bowl, The Simpsons became the longest-running animated series in prime time history, and Bill Clinton was sworn in for his second term as U.S. President. The end of Moore’s law was heralded at the 50th anniversary meeting of the ACM. Competition was heating up in the market for 56-kbit modems. And at EDN Magazine, a young technical editor looked out on the embedded industry and pondered the absence of any really good benchmarks for measuring the performance of embedded microprocessors. |
 |
That microprocessor editor at EDN was myself. Over the previous 12 months I had already become absorbed in the benchmark question through a “hands-on” project at the magazine, which eventually indicated the need for an organized effort to make industry-standard benchmarks a reality. The turning point was a meeting 10 years ago this month, in Boston, during the Embedded Systems Conference. I can still see myself standing in a hotel ballroom—it was somewhere adjacent to the Hines Convention Center—surrounded by 10 large round tables set with white tablecloths. ARM and National Semiconductor had sponsored the room and the lunch, and their representatives were among the 25 or so attendees from companies who would six months later become EEMBC’s founding members. Although many faces and names have changed, most of these companies—such as Analog Devices, ARM, Hitachi (now Renesas), IBM, LSI Logic, MIPS, Motorola (now Freescale), NEC, Philips (now NXP), QED (now PMC Sierra), SGS Thomson (now ST Micro), Siemens (now Infineon), Sun, Texas Instruments, and Toshiba—have been involved with EEMBC from that begin-ning and continue their support today, along with an additional 28 member companies. Markus Levy |
|
By Shay Gal-On, Director of Software Engineering
A little background
Profile guided optimizations are optimizations that are guided by information derived from a particular execution of the program, rather than by using heuristics to guess what an execution of the code is going to do. In technical terms, data flow analysis and control flow structuring can benefit from extra information. This information is called a profile. The profile, fed into an optimizer, usually enables more efficient optimizations. Typically, this information is used to enable optimizations that also incur a high potential for a penalty.
For example, consider the following simple case:
for (i=0; i<N; i++) {
if (a[i])
t+=1;
}
If the compiler has profile information that shows that N is divisible by 4, and that mostly a[i] is not 0, the compiler could “rewrite” this code to look like this:
if (N%4 != 0)
… do old code…
else {
for (i=0; i<N; i+=4) {
t+=4;
if (a[i+0]==0) t--;
if (a[i+1]==0) t--;
if (a[i+2]==0) t--;
if (a[i+3]==0) t--;
}
Obviously, this new code is much bigger than the previous, but it is potentially much faster. Consider for example that the new code must only modify t once for every four times that the original code modified it if the information in the profile is correct. Of course, if the actual values for N and a[i] are NOT like the values in the profile, this optimization will lead to code that is slower as well as bigger.
Some examples of optimizations that are usually driven by profile information are loop unrolling, register allocation and spill code generation, code layout to improve branch prediction, trace scheduling, predication, and PRE via speculation. The list goes on and even includes inter process optimizations.
Profile guided optimizations are practical in embedded systems where the same code is going to be executed for very long periods. Some systems take this a step further, and use profile information to select which source code gives the best result. The FFTW C subroutine library is just one example www.fftw.org.
Issues with PGO
There are two main issues with profile guided optimizations: the first and most important issue is that when profiling your code, you use training data that is representative of data the program will tackle in the real world. However, there is no guarantee that the training data is a good match for actual real world data.
The second issue is that the optimization process is now a multi-stage process:
1. Build the program as usual.
2. Run the program using a representative dataset and generate a profile.
3. Optimize the program, using the profile derived in step 2.
This optimization may require a complete rebuild of the whole program, or using special tools that optimize the binary.
This process means it takes longer to get the final executable, there are more potential failure points, and verification takes longer.
PGO and EEMBC
As part of our process, EEMBC benchmarks always use the same input data. Therefore, to mimic real world issues, we created special datasets for the training phase. These special datasets were synthetically created to cover input values that the code could potentially encounter, rather than to try and match “logical” values. In real applications, when training data is used, it is similarly generated statistically to cover as wide a range of inputs as possible. For example, looking visually at the training input to the bit manipulation algorithm from the automotive suite, you can see that the input covers all available input values, and also many combinations on the order at which particular inputs are encountered.
As pointed out above, the second issue with profile guided optimizations is the multi-stage process. The EEMBC infrastructure has been changed to accommodate this process using only a command line flag. While the process does take more computer time, the infrastructure shows an example of how the user does not have to experience most of the complexity involved in creating and using the profile data.
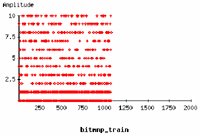
Visual Representation of training data for EEMBC
Bit Manipulation benchmark from AutoBench™ 1.1 automotive suite.
Results
Results of profile guided optimizations depend on the compiler toolchain used, the optimizations enabled, and the hardware architecture. For example, using GCC on a Windows-based x86 PC, profile guided optimizations on AutoBench™ 1.1 show about a 17% improvement for the combined Automark™ score. However, certain individual benchmarks in that suite actually performed worse (as much as 10%), while one benchmark performed as much as 70% faster than in the version that was optimized without using profile information.
Summary
EEMBC methodology now incorporates specific training datasets for all of the benchmark suites. The benefit from using profile guided optimizations depends on the quality of the tools used to produce the profile, as well as the tools using the profile to optimize the program.
Further Reading:
Profile Guided Compiler Optimizations (2002) by Rajiv Gupta, Eduard Mehofer, and Youtao Zhang
Home page of James Larus of Microsoft Research. See papers on path profiling.
Data flow frequency analysis (1996) by G. Ramalingam. From Proceedings of the SIGPLAN '96 Conference on Programming Language Design and Implementation, pages 267--277, 1996. (download Postscript file)
|
||||||||||||
EEMBC has gained two new members since the beginning of 2007. P.A. Semi joined the Consortium as a member of the Board of Directors, while NETCLEUS Systems Corporation joined as a member of the Networking subcommittee. P.A. Semi was established in 2003 by industry veterans including Dan Dobberpuhl, the lead designer of the DEC Alpha and StrongARM microprocessors and the first multicore system on chip, the SiByte 1250. P.A. Semi’s PWRficient™ processors are based on, and fully software compatible with, the highly regarded Power Architecture instruction set, licensed to P.A. Semi by IBM. NETCLEUS Systems, based in Japan, was founded in 1997 to develop LSI chips for ISDN applications. Today, the company is focused on developing innovative IP cores and LSI designs for data communication and network applications such as LAN and WLAN. EEMBC announced plans for its forthcoming multicore-enabled benchmarks in late February. The new benchmarks are intended to give an accurate indication of the value of transitioning from a single core to a multicore system, in addition to determining the impact of system-level bottlenecks, such as those encountered when moving data on and off a multicore chip. EEMBC plans to address this challenge with benchmarks that enable a standardized evaluation of the benefits of concurrent processing while providing the scalability needed to support any number of multiple cores. The effort is being led by John Goodacre of ARM, who serves as chair of EEMBC's multiprocessing workgroup. Non-member companies are encouraged to join the consortium now to participate in the final definition and testing stages. EEMBC is among the sponsors of an upcoming conference devoted to the Advanced Telecommunications Computing Architecture, an emerging standard platform for telecommunications equipment. The AdvancedTCA Summit takes place October 16-18 at the Santa Clara Convention Center. Further information is available at www.AdvancedTCAsummit.com. EnergyBench™, the EEMBC tool that shows the energy “cost” of processor performance, is the topic of a forthcoming article in Electronic Products magazine that shows the tool’s application to NXP Semiconductors’ LPC3180, an ARM-9 based microcontroller. Conclusion: Not all ARM9 devices are alike when it comes to power consumption. Authors are EEMBC’s Markus Levy and Shay Gal-On and NXP’s Rob Cosaro. Expected publication date is mid-April 2007. |