
Summer 2006
In This Issue
From the PresidentFrom the EEMBC Technology Center
New Benchmark Scores
News Briefs
EEMBC Calendar
Shay Gal-On, EEMBC director of software engineering, will present "A New Way To Benchmark Energy Cost of Embedded Processor Performance" at Embedded Systems Conference on September 27 at 8:30 a.m. at the Hynes Convention Center in Boston. Topics will include measurement techniques useful for system designers making tradeoffs between performance and power in portable and space-constrained applications, with a focus on benchmark projects currently under development and an exploration of applying benchmarks to derive execution profiles. Click for more information.
EEMBC President Markus Levy will present "Understanding the Critical Aspects of Microcontroller Performance" at the ARM Developer's Conference on October 3 at 1:00 p.m. The talk will discuss, among other topics, how the performance of ARM7 devices is highly dependent on the memory subsystem that surrounds them.
EEMBC President Markus Levy will be chairing the Multicore Processor Development Track on October 12 at the ESS2006 Technical Conference Programme in Birmingham, England. Additionally, Levy will be presenting on the challenges of designing a multicore system. Click for more information.
"New Trend of Benchmark Usages for Embedded Processors" is the title of a presentation being given by Steve Otsuka, EEMBC Japan Representative, at the CQ Publishing Technology Seminar and Exhibition, being held October 13 at the Akihabara Convention Hall in Tokyo. Click for more information.
An introduction to multicore benchmarks from EEMBC will be addressed in presentations by Markus Levy at the Japan Multicore Expo (October 31 – November 1, co-located with the Embedded Processor Symposium in Tokyo) and the Germany Multicore Expo (November 14-15, at electronica 2006 in Munich). Click for more information.
| Letter from the President For those of you who have ever been a member of a consortium, you probably have experienced the amount of effort and time required to move things along. Every consortium has its share of policies and processes that it must endure in order to "get things right" and satisfy the majority of its membership. EEMBC is no exception to this, and as a result, it traditionally has taken us a relatively long time to develop |
 |
and test each new benchmark suite that comes about. In the 2005 issue of Microprocessor Report, Tom Halfhill used the adjective "glacial" to describe the pace of EEMBC benchmark development. That might have been a fair description at the time, but since then we've been experiencing a climate change. As a matter of fact, I am quite excited about the flood of new benchmarks and other projects that are currently under development within EEMBC. Markus Levy |
|
From the EEMBC Technology Center
By Shay Gal-On, Director of Software Engineering
One of the most exciting EEMBC projects now underway is a study of the workload characteristics of all the EEMBC benchmarks. In addition to looking at ICache and DCache effects, we also plan to analyze the inherent fine grain parallelism of the code, the inherent branch misprediction or control behavior of benchmarks, and the dynamic rate of different types of instructions. This study is being done using several popular architectures and special analysis tools.
![]()
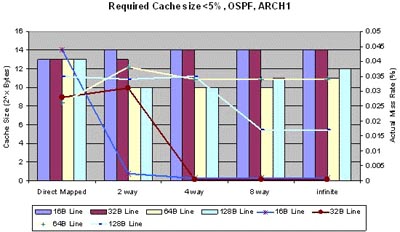
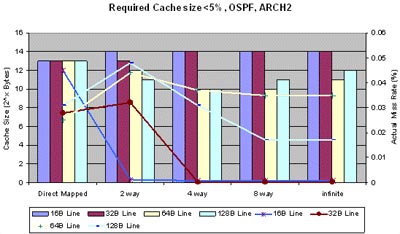
To give you a more concrete idea of what this project is about, here are a couple of initial results from an analysis of the Networking 1.1 OSPF benchmark. The objective was to determine the minimum data cache size required to limit the miss ratio to some negligible amount. We also wanted to study the effects of associativity and cache line size relative to the minimum required cache size. Results from two separate popular RISC architectures are shown in the graphs below.
![]()
![]()
To help make sense of all this data, the graphs show both required cache size, as well as the actual miss ratio. As you can see, both architectures show several similar trends:
• Both architectures achieve minimum cache size using 4-way associative cache, with 64B or 128B line size. Lines shorter then 64B require a substantially bigger cache to achieve a miss rate below 5%, although the actual miss rate is actually less than 0.1%. In other words, by forcing the miss rate below 5%, the miss rate actually gets close to zero.
• When using a cache line size of less then 64B, direct mapped cache is actually superior to associative cache.
![]()
The next step is to examine the benchmark and see what happens if we change the minimum required cache miss ratio to be under 10%, or 1% or 0.1%. Actually, the ultimate "next step" is analyzing all the data we are collecting. For the time being, the goal of this project is to find the trends, which are already looking quite interesting. Stay tuned, we’ll be sharing those trends with you in the near future.
|
||||||
Measuring the "Power" Cost of Processor Performance Using EEMBC EnergyBench™ Benchmarks, a webcast presented by National Instruments on July 19, is now available for playback on demand by clicking on this link. EEMBC's Shay Gal-On and NI's Jared Aho are the webcast's co-presenters, providing an overview of how EEMBC has implemented EnergyBench using the LabVIEW platform and an affordable data acquisition (DAQ) card, both from National Instruments, to allow designers to compare the performance/energy of devices from multiple vendors side by side and select the processors that best fit their needs based on more accurate data. In other EnergyBench news, EEMBC wishes to thank its friends at NXP, the new semiconductor company founded by Philips, for their work on an EnergyBench demo board that will be used in future EEMBC presentations to show the capabilities of EnergyBench. Benvenuto! A seven-page overview article on EEMBC and its benchmarks will appear in the October 2006 issue of Firmware, marking the fullest treatment of the consortium ever presented in the Italian language. Co-authors are Markus Levy and Maurizio Del Corso, the magazine’s executive director. Firmware is the only Italian publication exclusively devoted to embedded processors and their applications. More info: http://www.fwonline.it. New from Tensilica's Steve Leibson, Designing SOCs with Configured Cores: Unleashing the Tensilica Xtensa and Diamond Cores, is an essential reference for system-on-chip designers that uses EEMBC benchmarks to compare Tensilica cores with competitive devices. Order your copy today at Amazon.com. Steve will be happy to autograph all purchased books; ask Markus to arrange it. |